


- IO涉及的知识是比较多的,我们选择性的学习,主要从三个方面来学习,IO的底层原理,序列化与反序列化,dex文件加固;
一.Android人员对于IO的诉求
1.1.IO对于系统的影响
- 性能层面基础的单位影响
- 使用率:是指磁盘处理io的时间百分比。过高的使用率(比如超过80%),通常意味着磁盘io存在性能瓶颈;
- 饱和度:是指磁盘处理io的繁忙程度。过高的饱和度,意味着磁盘存在着严重的性能瓶颈。当饱和度为100%时,磁盘无法接受新的io请求;
- IOPS:是指每秒的io请求数,适用于大量小文件的情景;
- 吞吐量:是指每秒的io请求大小,适用与大文件的情景响应时间:是指io请求从发出到收到响应的时间间隔;
1.2.Android对于IO需要注意的场景
- 设备(手机)作为S端
- IO复用可能导致的空指针
- 设备数据的传递
- dex加壳与脱壳
IO的优化是在解决CPU的瓶颈问题,但是通常在C端或少会出现,所以在学习IO的角度上来说,我们不会把重点放在CPU瓶颈的解决,而是会探寻IO本质原理及序列化的应用与Dex文件的加壳脱壳;
二.IO的基本常识-内核空间
- 在对于IO学习之前,我们首先需要了解一定的常识,比如内核、JVM、堆区、这些概念是必备的,JVM、堆栈之前笔记都有写过,这里提及一下内核;
- 简单理解内核:是一套软件,操作系统用于支撑基础使用的功能程序(可以学习一下操作系统的知识,推荐学习《操作系统之哲学原理》);
三.数据读写的方案
- IO的底层原理,实际上是调用内核的函数库,进行数据同步之后,然后由内核将数据写入到磁盘;
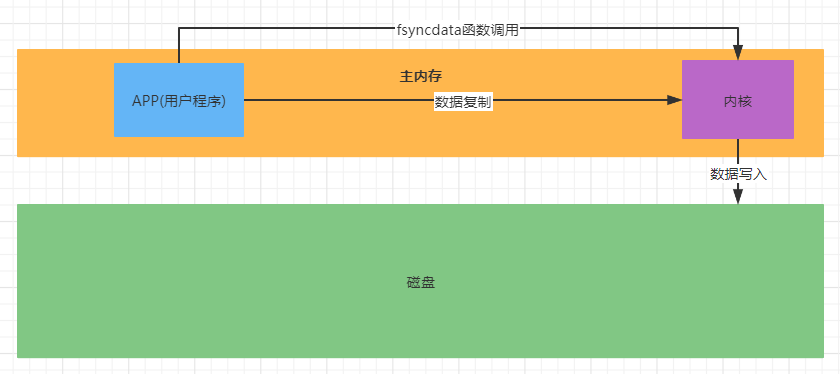
- 内核把数据写入到磁盘典型的操作方案:IO阻塞模型;
- 30 — 画图
四.内核(linux)的IO栈
- 我们可以把Linux存储系统的IO栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层;
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据;
- 通用块层,包括块设备io队列和io调度器。它会对文件系统的io请求进行排队,再通过重新排序和请求合并,然后才发送给下一级的设备层;
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的io操作;
- 存储系统的io,通常是整个系统中最慢的一环。所以,Linux通过多种缓存机制来优化io效率;为了优化存储系统访问文件的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以及减少对下层块设备的直接调用;为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据;
五.内核空间对于IO的操作方案
- 基础概念
- 页:4K数据为一页, 一页数据是IO操作的基本单位;
- 空间局部性原理:在常规操作下, 如果数据量较大的情况下可能会出现预占位4~16K的情况;
- 系统在进行IO操作的时候,会有一组优化方案存在,每次操作的数据为4K1页,但是为了优化可能会拓展到8K,在分配具体物理内存的时候8K数据占用8K数据,若还是不断地写,会提前给8K或16K,下次,若空间够用了就不分配了,不够的情况下,再分配;
六.IO模型
- IO分两阶段进行:
- 1.数据准备阶段;
- 2.内核空间复制回用户进程缓冲区阶段;
- 所谓模型就是在这两阶段当中的实现方案;
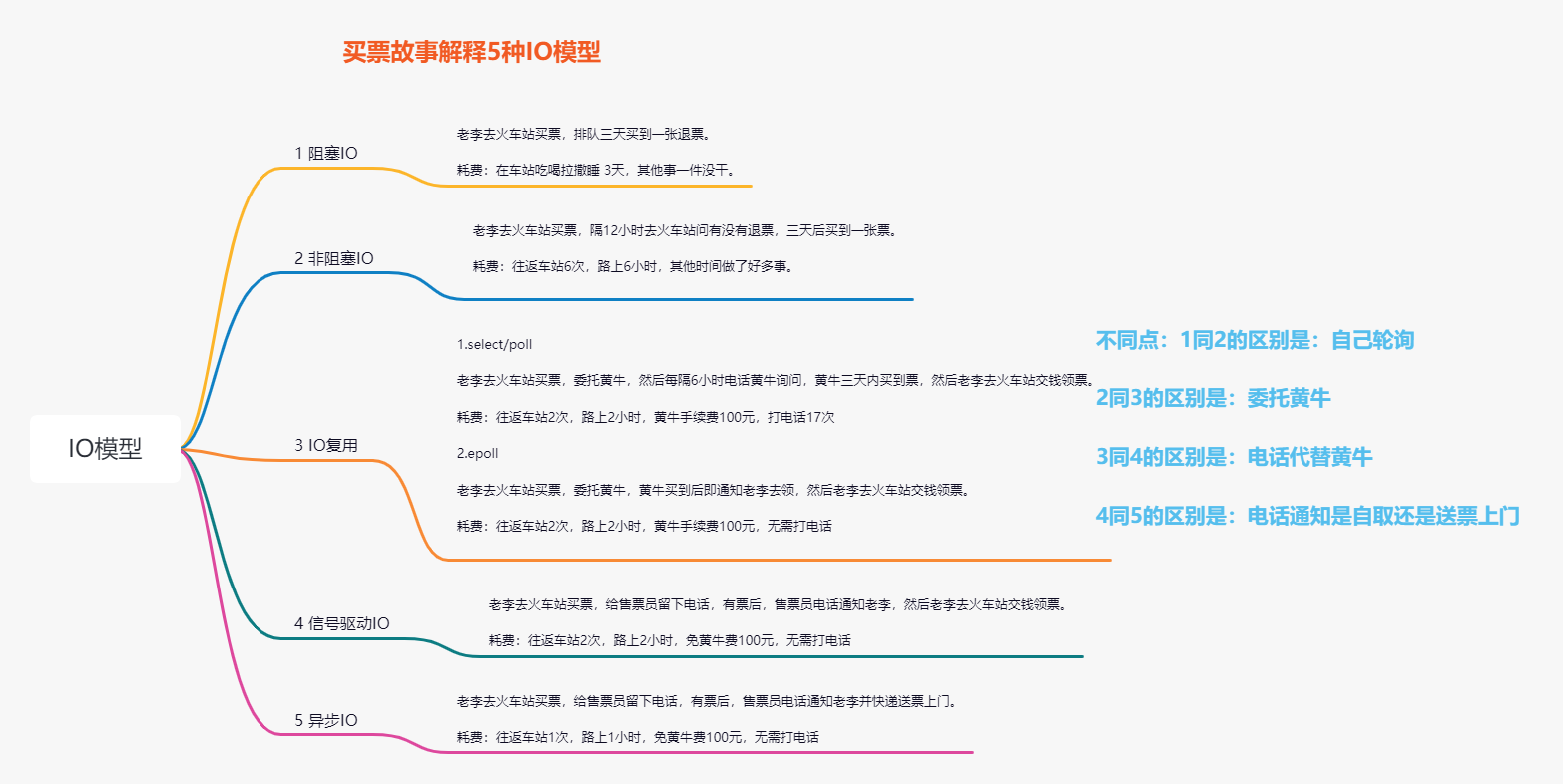
七.阻塞IO和非阻塞IO
- 阻塞IO
- 数据还没有准备好,内核阻塞住等待数据过来,过来之后继续执行下面的动作;
- 缺点:在高强度的并发情况下,很容易将CPU拉满,内存处理需要有线程,内核建立联系,对CPU造成损耗;
- 非阻塞IO
- 在等待的时候会去做轮询操作,其它业务照常运行;
- 整体性能有很好的提升;
八.JAVA IO的分类
- Java对于IO提供了N多方案的支撑
- 注意点:RandomAccessFile
- 从功能上讲提供定位处理;
- 缓冲区上讲,提供了MapperByteBuffer,这个是内核与APP缓冲区共享;
- 注意点:RandomAccessFile
- 缓冲区概念
- 因为基础IO的相关处理方案,每一次写入都会直接调用复制,在当前程序,将数据缓存起来,然后到达8K一次性写出;

8.1.标准/基础IO
- 特点:每一次写数据的时候都会将数据写进去;
- 标准/基础IO流没有所谓的flush概念(其方法是空实现,没有任何缓冲的概念);
- 每一次的基础IO都会涉及调用内核函数,会频繁的产生复制;
- IO使用层面最容易出现的问题,频繁的进行IO读写使用了基础的IO流;
8.2.Java IO应用场景demo
package com.kerwin.io01;
import org.junit.Test;
import java.io.BufferedOutputStream;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
import java.io.PrintStream;
import java.io.RandomAccessFile;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class IODemo {
File file = new File("D:/a.txt");
public void initFile() throws Exception{
file = new File("d:/a.txt");
if(file.exists()){
file.delete();
}
file.createNewFile();
}
/**
* 标准文件输出,
* IO概念汇总,一切皆文件
* @throws Exception
*/
public void fileIO() throws Exception {
//标准/基础IO
//基础IO都会有一个特点
//IO使用层面最容易出问题的是,频繁的进行IO读写的情况下你用了基础IO流
FileInputStream in = new FileInputStream(file);
FileOutputStream out = new FileOutputStream(file);
for (int i = 0; i < 10000; i++) {
out.write("hello ".getBytes());
}
//缓冲区????
out.flush();
out.close();
byte[] data = new byte[1024];
int lines = in.read(data);
in.close();
System.out.println(new String(data));
}
/**
* 设置缓冲区
* @throws Exception
*/
public void fileBufferedIO() throws Exception {
FileOutputStream out = new FileOutputStream(file);
BufferedOutputStream bos = new BufferedOutputStream(out);
bos.write("hello ".getBytes());
bos.write("world\n".getBytes());
bos.write("hello world! ".getBytes());
bos.flush();
bos.close();
}
/**
* 在内存里面开辟字节数组,然后将数据存入
* 缓存数据适用,数据放入内存中提速
* @throws Exception
*/
public void memIO() throws Exception {
//没有数据复制到内核的概念
//他就是在自己的堆区内部搞了一个数组在玩
ByteArrayOutputStream out = new ByteArrayOutputStream(1024);
BufferedOutputStream bos = new BufferedOutputStream(out);
bos.write("hello ".getBytes());
bos.write("world\n".getBytes());
bos.write("hello world! ".getBytes());
bos.flush();
bos.close();
}
/**
* 本质上是转换成字符流输出
* @throws Exception
*/
public void printIO() throws Exception {
ByteArrayOutputStream out = new ByteArrayOutputStream(1024);
PrintStream bos = new PrintStream(out);
bos.println("hello!");
bos.close();
}
/**
* 类型转换输出
* @throws Exception
*/
public void dataIO() throws Exception {
DataInputStream dis = new DataInputStream(new FileInputStream(file));
DataOutputStream dos = new DataOutputStream(new FileOutputStream(file));
// dos.writeInt();
}
/**
* 对象序列化传输
* @throws Exception
*/
public void objectIO() throws Exception{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
Object obj = new Object();
oos.writeObject(obj);
oos.flush();
oos.close();
}
/**
* 多线程通信
* 输入输出绑定,一边读,一边写
* @throws Exception
*/
@Test
public void pipedIO() throws Exception{
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream(pos);
pos.write("hello".getBytes());
pos.flush();
byte[] inData = new byte[1024];
pis.read(inData);
System.out.println(new String(inData));
pis.close();
pos.close();
}
/**
* 上传下载,或者特殊文件接受中进行文件的全量分析
* 大数据并行计算(一个巨量文件,设置偏移量进行拆解文件)
* @throws Exception
*/
@Test
public void randomIO() throws Exception{
//读写一体
//基础流--->复制函数调用频繁
RandomAccessFile raf = new RandomAccessFile(file,"rw");
raf.write("hello world!\nhello world!\nhello world!".getBytes());
System.out.println("第一次写入完成....");
Thread.sleep(10000);
raf.seek(15);
raf.write("xxxx".getBytes());
Thread.sleep(5000);
raf.close();
System.out.println("第二次写入完成....");
}
/**
* 断点续传,断点下载
* 做数据分析,大数据里面应用的
* 文件数据-》计算
* 并行计算
* 起始位置,偏移量 0,1000--》等于1个文件 --》1001,2000
* @throws Exception
*/
public void receiveFile() throws Exception{
ServerSocket connectSocket = null;
Socket socket = null;
DataInputStream dis;
DataOutputStream dos;
RandomAccessFile rad;
connectSocket = new ServerSocket(8080);
socket = connectSocket.accept();
dis = new DataInputStream(socket.getInputStream());
dos = new DataOutputStream(socket.getOutputStream());
if (true) {
String filename = dis.readUTF();//第一次交互查看文件名
System.err.println(filename);
dos.writeUTF("ok");//交互确认信息
dos.flush();
rad = new RandomAccessFile(filename, "rw");
ReceiveFile receiveFile = new ReceiveFile();
Long receiveFileSize = receiveFile.selectFile(filename);//查看已下载的文件大小
dos.writeLong(receiveFileSize);//发送已接收的大小
dos.flush();
long sendFileSize = dis.readLong();//已发送出来的文件大小
//如果文件已存在则重新下载
if (receiveFileSize >= sendFileSize) {
System.err.println("文件已存在");
}
else {
rad.seek(receiveFileSize);
int length;
byte[] buf = new byte[1024];
while ((length = dis.read(buf)) != -1) {
rad.write(buf, 0, length);
}//接收文件
System.out.println("end");
}
}
}
/**
* 操作大文件的方式
* @throws Exception
*/
@Test
public void mappedBateBuffer() throws Exception{
initFile();
RandomAccessFile raf = new RandomAccessFile(file,"rw");
raf.write("hello world!\nhello world!\nhello world!".getBytes());
System.out.println("第一次写入完成....");
Thread.sleep(10000);
FileChannel channel = raf.getChannel();
//缓冲区
MappedByteBuffer byteBuffer = channel.map(FileChannel.MapMode.READ_WRITE,channel.position(),channel.size());
//之前的理论支撑,这里会进去吗?不会,因为没有复制,这些数据也没有达到8K
//为什么?
byteBuffer.put("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx".getBytes());
System.out.println("第二次数据转入缓存");
Thread.sleep(10000);
raf.close();
}
}
8.3.MappedByteBuffer缓冲区
-
属于NIO(非阻塞IO,从应用层面来讲,是JDK提供一套基于非阻塞实现方案所推出来的相关的API)内容;
-
Java IO操作中通常采用BufferedReader,BufferedInputStream等带缓冲的IO类处理大文件,不过Java NIO中引入了一种基于MappedByteBuffer操作大文件的方式,其读写性能极高;
-
FileChannel提供了map方法把文件映射到虚拟内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射;
-
MappedByteBuffer使用虚拟内存,因此分配(map)的内存大小不受JVM的-Xmx参数限制,但是也是有大小限制的;
-
如果当文件超出1.5G限制时,可以通过position参数重新map文件后面的内容;
-
MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的;
九.OKIO
-
OkHttp团队自己对于IO这一块写了一套,底层还是Java的Basic IO;
-
专门针对网络进行处理的;
OKIO核心是解决双流操作的问题
9.1.OKIO对于JAVAIO的优化
官方的解释是这样的:Okio是一个库,是对java.io和java.nio的补充,通过这个库,我们可以更简单的使用和存储我们的数据。
Okio提供了两种新的类型,这两种类型有很多新的功能,并且使用比较简单。这两中类型分别是:ByteString和Buffer。
ByteString是不可变的字节序列(请参考String,String是不可变的字符串)。String是基本的字符数据,ByteString相当于是String的兄弟,ByteString让处理二进制数据变得简单了。这个类是符合人们的编程习惯的,它知道怎么使用比如hax,base64,UTF-8等编码格式将它自己编码或解码。
Buffer是一个可变的字符序列。你不需要提前设置它的大小,它在写入数据的时候会将数据放在最后,而在读取的时候会在最前面开始读取(这很类似与队列),你也不需要关心它的位置,限制,容量等等。
9.2.OKIO采取的方案
OK在读取数据时,先从Buffer对象中获取了一个Segment,然后向Segment中读取数据,每个Segment最多可以存入8K数据。这里需要提一下Buffer中数据的数据结构,Buffer中的数据是存在于一个双向链表中,链表中的每个节点都是一个Segment
9.3.OKIO解决了什么
不管是读入还是写出,缓冲区的存在必然涉及copy的过程,而如果涉及双流操作,比如从一个输入流读入,再写入到一个输出流,那么这种情况下,在缓冲存在的情况下,数据走向是:
-> 从输入流读出到缓冲区
-> 从输入流缓冲区copy到 b[]
-> 将 b[] copy 到输出流缓冲区
-> 输出流缓冲区读出数据到输出流
OKIO是将两个缓冲合并成一份
9.4.OKIO采取的方案
Okio核心竞争力为,增强了流于流之间的互动,使得当数据从一个缓冲区移动到另一个缓冲区时,可以不经过copy能达到:
以Segment作为存储结构,真实数据以类型为byte[]的成员变量data存在,并用其它变量标记数据状态,在需要时,如果可以,移动Segment引用,而非copy data数据
Segment在Segment线程池中以单链表存在以便复用,在Buffer中以双向链表存在存储数据,head指向头部,是最老的数据
Segment能通过slipt()进行分割,可实现数据共享,能通过compact()进行合并。由Buffer来进行数据调度,基本遵守 “大块数据移动引用,小块数据进行copy” 的思想
Source 对应输入流,Sink 对应输出流
TimeOut 以达到在期望时间内完成IO操作的目的,同步超时在每次IO操作中检查耗时,异步超时开启另一线程间隔时间检查耗时
十.总结
- IO原理:本质是内核提供的函数,功能由内核完成;
- JAVA提供的IO是依托于内核函数的一个实现;
评论区